If you have ever used ChatGPT, you know the feeling: you ask a question, and then you wait. Sometimes a second, sometimes ten, sometimes much longer. For complex tasks it can feel like an eternity.
Now imagine the answer arriving so fast you barely notice the delay. That is where the stack is heading over the coming months, and it is coming from two different directions at once.
What Just Happened?
Within days, two companies made announcements that together send a very clear signal: the way AI hardware is built is about to change fundamentally.
Taalas: The AI Model Burned Directly into the Chip
Taalas, a hardware startup with 24 people, unveiled a chip that does not run AI models on standard graphics cards. Instead, the model is hard-wired directly into the silicon, permanently etched into the chip. The result:
“Taalas’ silicon Llama achieves 17K tokens/sec per user, nearly 10X faster than the current state of the art, while costing 20X less to build, and consuming 10X less power.” Source: The path to ubiquitous AI (Taalas) | Demo: chatjimmy.ai
In plain terms: 10 times faster than anything available today. 20 times cheaper to manufacture. At one tenth the power consumption.
How dramatic the gap to the previous leaders is becomes clear in this benchmark comparison:
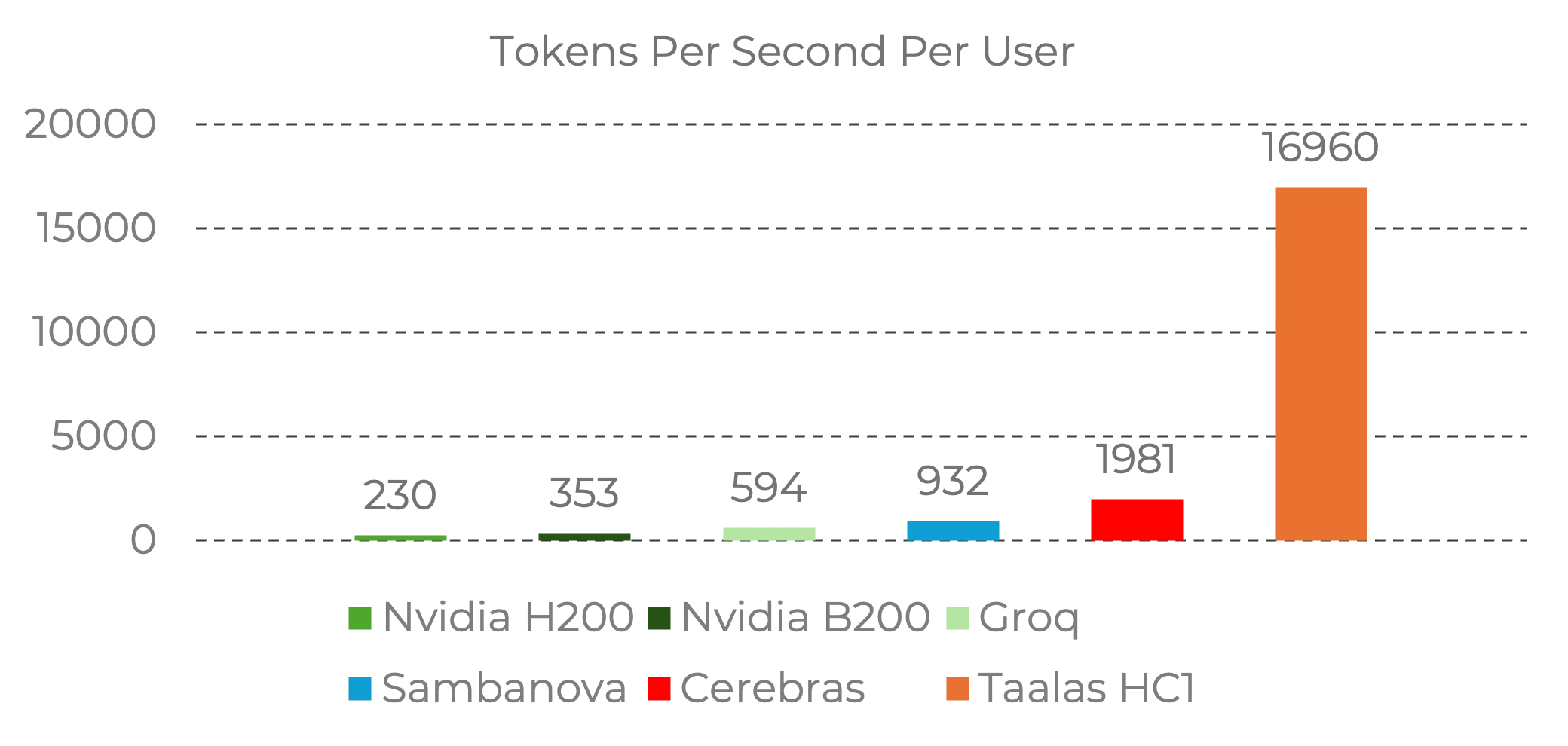 Source: Taalas | Performance data for Llama 3.1 8B
Source: Taalas | Performance data for Llama 3.1 8B
What jumps out immediately: Cerebras is still the king for fast, strong production models today. Cerebras delivers up to 15x faster inference than Nvidia GPUs and remains the practical benchmark for many teams. Taalas, however, shows an extreme speed signal on hard-wired Llama 3.1 8B. This is not someone breaking the speed record by 10% — it is beating it by a factor of ten, but so far on a narrower model class.
If you want to experience it yourself: Taalas offers a public demo at chatjimmy.ai where the hard-wired Llama model runs live.
OpenAI: Codex Spark Runs on Cerebras, Not Nvidia
Almost simultaneously, OpenAI released GPT-5.3 Codex Spark, a new model built specifically for programming. The key detail: it does not run on the usual Nvidia GPUs but on Cerebras hardware — the platform that is still widely treated as the current speed reference for high-capability inference.
“Codex-Spark runs on Cerebras’ Wafer Scale Engine 3 … a purpose-built AI accelerator for high-speed inference giving Codex a latency-first serving tier.” Source: Introducing GPT-5.3 Codex Spark (OpenAI)
Codex Spark generates code at over 1,000 tokens per second — 15x faster than conventional GPU hardware — with 128k context. For developers, that means more iterations in the same time, faster feedback, fewer context switches.
So even OpenAI is no longer using Nvidia for its fast coding tier — it is using specialized hardware. And Taalas simultaneously shows that, for a hard-wired smaller model, even more raw speed is possible.
Why Speed Suddenly Changes Everything
For context: until recently, a simple rule governed AI inference. As long as the model responded faster than a human could read, speed was sufficient. More speed was nice-to-have, not a game-changer.
That changed fundamentally with the rise of reasoning models. Since OpenAI’s first reasoning model in late 2024, AI systems achieve higher accuracy by working through additional thinking steps: planning, checking intermediate results, self-correcting before answering. Agentic AI goes further still, running multiple reasoning loops, often with tool calls and real-world actions.
The problem: all those thinking steps cost time. On conventional GPU hardware, “more accurate” automatically means “slower.” And the more complex the task, the longer the wait.
Cerebras was the first to articulate this clearly: faster inference is not just a UX feature — it is an accuracy lever. If you can infer faster, you can run more thinking steps within the same latency budget and arrive at better results. Cerebras calls this the “Cerebras Scaling Law”:
“If you could run inference faster, you could reason more inside the same latency budget — trading surplus speed for higher-accuracy results.” Source: Speed and Accuracy (Cerebras)
Production data confirms this: according to OpenRouter’s 2025 State of AI study, more than half of all processed tokens now come from reasoning models. Demand for compute is exploding, and faster hardware is becoming not just a comfort feature but a prerequisite for accurate results.
Why AI Inference on GPUs Is So Slow
For everyone
AI today runs on massive clusters of graphics cards. Those clusters consume enormous amounts of electricity, need heavy infrastructure, and cost hundreds of millions to build. That is one reason AI services are expensive and responses can take time.
The root problem: an AI model is far too large to fit entirely into a GPU’s fast on-chip memory. So data must constantly be shuffled between slow and fast memory. And during that shuffling, the graphics card sits idle most of the time, waiting.
For developers
Autoregressive inference consists of two phases: prefill (parallelizable) and decode. Decode is the bottleneck: even with KV caching, each new token requires a complete forward pass, sequentially.
Even today’s smallest models are hundreds of times larger than a GPU’s on-chip memory. That is why every GPU integrates an HBM (High Bandwidth Memory) module, connected via a relatively narrow memory bus with single-digit TB/s bandwidth. GenAI inference is memory-bandwidth-bound: compute units sit idle waiting for weights to arrive from HBM.
“GPU compute typically sits idle while memory traffic and communication overhead quickly become the bottleneck, especially as models scale and context grows.” Source: Speed and Accuracy (Cerebras)
Two Radically Different Solutions
Cerebras: The World’s Largest Chip
Cerebras tackles the memory problem head-on. Instead of dicing a wafer into small chips and then stitching them back together with external memory and interconnects, Cerebras leaves the entire wafer as a single processor. The Wafer Scale Engine 3 is 5x larger than Nvidia’s B200, with compute and SRAM tightly interwoven on one die.
The system consists of a network-attached accelerator and a CPU cluster that streams data to the accelerator at extreme speeds using a chief/worker model. The result: massively higher on-chip bandwidth, no memory bottleneck, up to 15x faster token generation than GPUs.
Real production examples show what that means: AlphaSense processes 100x more documents in half the time on Cerebras. Tavus achieves ~2,000 tokens/sec for real-time video conversations. OpenAI’s Codex Spark generates code at over 1,000 tokens/sec.
Taalas: The Model Becomes the Chip
Taalas goes a step further. Instead of building a faster general-purpose accelerator, they burn each individual AI model into its own silicon. The company calls its products “Hardcore Models” — models that have literally become hardware.
This is based on three principles:
- Total specialization. A chip that runs exactly one model wastes no transistor on flexibility.
- Merging storage and compute. Instead of shuttling data between separate memory and compute chips, Taalas unifies both on a single die at DRAM-level density.
- Radical simplification. No HBM, no advanced packaging, no 3D stacking, no high-speed I/O.
“The result is a system that does not depend on difficult or exotic technologies, no HBM, advanced packaging, 3D stacking, liquid cooling, high speed IO.” Source: The path to ubiquitous AI (Taalas)
The analogy Taalas draws is apt: ENIAC was a room-filling beast of vacuum tubes and cables. ENIAC introduced humanity to the magic of computing but was slow, costly, and unscalable. The transistor sparked the real revolution — through workstations and PCs to smartphones and ubiquitous computing. General-purpose computing entered the mainstream by becoming easy to build, fast, and cheap. AI needs to follow the same path.
What You Should Know Before Getting Too Excited
Both developments are impressive, but there are important caveats:
Regarding Taalas:
- The first product runs a relatively small model (Llama 3.1 8B), not a frontier model.
- Aggressive quantization (3-bit and 6-bit parameters) introduces quality degradation compared to GPU benchmarks. Taalas communicates this openly.
- The second generation (HC2) will support standard 4-bit floating-point formats and address these limitations.
- Roadmap: a mid-sized reasoning LLM is expected in spring, a frontier LLM on HC2 in winter.
Regarding Cerebras:
- Cerebras demonstrably delivers production performance at major customers. But the wafer-scale approach has its own challenges in yield and scaling.
- The Codex Spark integration is a research preview for ChatGPT Pro users, not yet a broad production deployment.
“15x faster generation, 128k context, now in research preview for ChatGPT Pro users.” Source: Introducing GPT-5.3 Codex Spark (OpenAI)
What Actually Changes
For everyone who uses AI day to day
-
Less waiting on long tasks. Many everyday prompts are already fast enough. The bigger gain is on complex tasks where you currently wait 30-120 seconds. That is where higher throughput can push wait times down to just a few seconds.
-
More accurate results in the same time. When hardware computes faster, AI can think more before it answers — and still finish sooner than before. More speed means not just less waiting, but better answers.
-
Cost structure can shift. If hardware really becomes much cheaper and more efficient, margins per request improve. Whether providers pass that through as lower prices is still a business decision, but the economic pressure grows.
-
AI can go to more places. When an AI chip no longer needs an entire data center but fits on a single board, entirely new use cases open up. AI running directly in your company — no cloud, no data leaving the building.
For developers and tech teams
-
Agentic workflows get faster. Agentic workflows already work today. More inference speed mainly improves iteration loops and reduces dead time between tool calls, reviews, and fixes.
-
Use speed as an accuracy lever. Deploying on faster hardware means you can fit more reasoning steps into the same latency budget. This opens a new optimization space: not just answering faster, but answering better — in the same amount of time.
-
Codex Spark shows the direction. OpenAI’s decision to run a model on Cerebras instead of Nvidia is an architectural statement. Latency-first serving is becoming its own infrastructure tier.
-
The GPU monopoly is being questioned. Until now, the answer to “make AI faster” was always: buy more Nvidia cards. Cerebras and Taalas show two different paths where specialized hardware fundamentally challenges that assumption. And other ASIC vendors, according to Cerebras, only deliver low single-digit speedups over GPUs because they share the same fundamental limitations of small chips.
What This Means for Mid-Market Companies
This is not just a Silicon Valley topic. When AI gets faster and cheaper, smaller companies benefit the most. They could never afford massive GPU clusters and had to rely on cloud services where every request costs money.
Specialized, affordable AI hardware could mean, in the medium term: your own AI systems on-premise, fast, privacy-compliant, and within budget. No subscription model, no dependency on US cloud providers.
And there is a concrete signal from practice: Taalas brought its first product to market with a team of 24 people and total costs of $30 million. That shows it does not take hundreds of billions to develop relevant AI hardware.
Conclusion
We are still early. Taalas’ chips currently run only a smaller model. The Cerebras integration at OpenAI is a research preview. But the direction is clear: the era of “waiting for the AI to finish thinking” is coming to an end.
What is emerging is a paradigm shift — away from ever-larger GPU farms, toward specialized hardware that makes AI fast, affordable, and accessible everywhere. The ENIAC era of AI is ending. What comes next is likely to change AI fundamentally.
Sources
- Taalas: The path to ubiquitous AI
- Taalas Demo: chatjimmy.ai
- OpenAI: Introducing GPT-5.3 Codex Spark
- Cerebras: Speed and Accuracy
- Cerebras: How Cerebras Works
Would you like to assess which AI applications already make sense in your company today and what role speed, data privacy, and cost efficiency will play going forward? Then start with a potential analysis. Together, we examine where real value can be created in your company and which developments are strategically relevant for you.