Wer ChatGPT nutzt, kennt das: Man stellt eine Frage, und dann wartet man. Manchmal eine Sekunde, manchmal zehn, manchmal deutlich länger. Bei komplexeren Aufgaben fühlt sich das an wie eine Ewigkeit.
Jetzt stellt euch vor, die Antwort käme so schnell, dass ihr den Unterschied zum Tippen kaum noch merkt. Genau das zeichnet sich für die nächste Zeit ab, und zwar aus zwei verschiedenen Richtungen gleichzeitig.
Was ist passiert?
Innerhalb weniger Tage haben zwei Unternehmen Ankündigungen gemacht, die zusammen ein ziemlich klares Signal senden: Die Art, wie KI-Hardware gebaut wird, steht vor einem fundamentalen Umbruch.
Taalas: Das KI-Modell direkt in den Chip eingebrannt
Taalas, ein Hardware-Startup mit 24 Leuten, hat einen Chip vorgestellt, der KI-Modelle nicht wie üblich auf Grafikkarten laufen lässt. Stattdessen wird das Modell direkt in den Chip eingebrannt, fest verdrahtet im Silizium. Das Ergebnis:
“Taalas’ silicon Llama achieves 17K tokens/sec per user, nearly 10X faster than the current state of the art, while costing 20X less to build, and consuming 10X less power.” Quelle: The path to ubiquitous AI (Taalas) | Demo: chatjimmy.ai
In einfachen Worten: 10-mal schneller als alles, was es bisher gibt. 20-mal günstiger in der Herstellung. Und das bei einem Zehntel des Stromverbrauchs.
Wie dramatisch der Unterschied ist, zeigt dieser Benchmark-Vergleich:
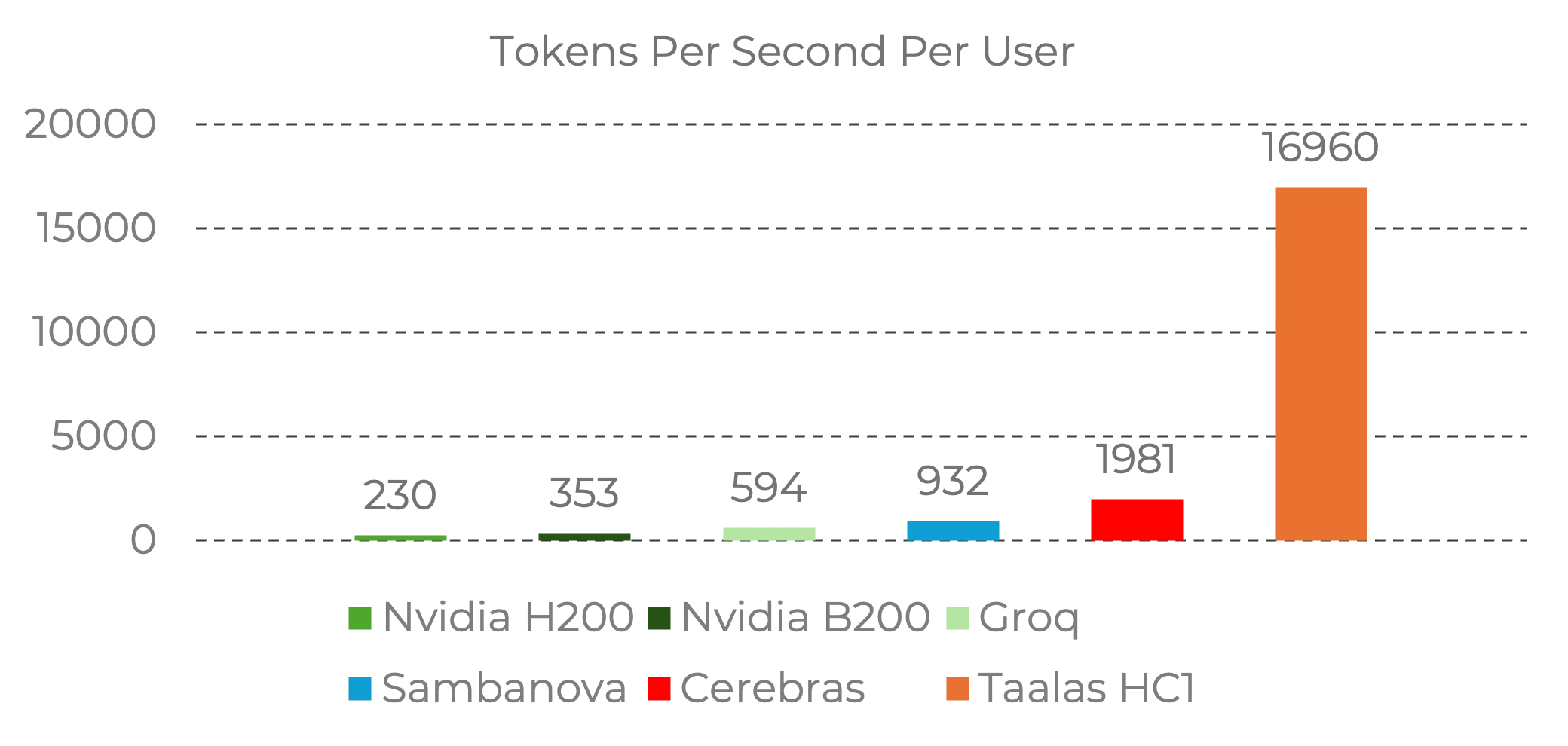 Quelle: Taalas | Performance-Daten für Llama 3.1 8B
Quelle: Taalas | Performance-Daten für Llama 3.1 8B
Was an dieser Grafik sofort auffällt: Cerebras bleibt aktuell der King bei schnellen, starken Produktionsmodellen. Cerebras liefert bis zu 15-mal schnellere Inferenz als Nvidias GPUs und ist für viele Teams weiterhin der praxisrelevante Standard. Taalas zeigt allerdings beim fest verdrahteten Llama 3.1 8B ein extremes Geschwindigkeitssignal. Das ist, als würde jemand den bisherigen Geschwindigkeitsrekord nicht um 10 % brechen, sondern um das Zehnfache — aber bisher auf einer engeren Modellklasse.
Wer es selbst erleben will: Taalas bietet unter chatjimmy.ai eine öffentliche Demo an, bei der das fest verdrahtete Llama-Modell live läuft.
OpenAI: Codex Spark läuft auf Cerebras, nicht auf Nvidia
Fast zeitgleich hat OpenAI mit GPT-5.3 Codex Spark ein neues Modell speziell für Programmierung veröffentlicht. Das Besondere: Es läuft nicht auf den üblichen Nvidia-Grafikkarten, sondern auf Cerebras-Hardware — also auf dem Anbieter, der aktuell bei schnellen, leistungsstarken Inferenz-Setups weiterhin als Referenz gilt.
“Codex-Spark runs on Cerebras’ Wafer Scale Engine 3 … a purpose-built AI accelerator for high-speed inference giving Codex a latency-first serving tier.” Quelle: Introducing GPT-5.3 Codex Spark (OpenAI)
Codex Spark generiert Code mit über 1.000 Tokens pro Sekunde, 15-mal schneller als auf herkömmlicher GPU-Hardware, bei 128k Kontext. Für Entwickler:innen heißt das: Mehr Iterationen in derselben Zeit, schnelleres Feedback, weniger Kontextwechsel.
Das heißt: Selbst OpenAI setzt für sein schnelles Programmiermodell nicht mehr auf Nvidia, sondern auf Spezialhardware. Und Taalas zeigt gleichzeitig, dass es bei einem hart verdrahteten, kleineren Modell noch deutlich mehr Rohgeschwindigkeit geben kann.
Warum Geschwindigkeit plötzlich alles verändert
Um das einzuordnen: Bis vor Kurzem galt bei KI-Inferenz eine einfache Regel. Solange das Modell schneller antwortet, als ein Mensch lesen kann, reicht die Geschwindigkeit. Mehr Speed war ein Nice-to-have, kein Game-Changer.
Das hat sich mit dem Aufkommen von Reasoning-Modellen fundamental geändert. Seit OpenAIs erstem Reasoning-Modell Ende 2024 erreichen KI-Systeme höhere Genauigkeit, indem sie in zusätzlichen Denkschritten arbeiten: planen, Zwischenergebnisse prüfen, sich selbst korrigieren, bevor sie antworten. Agentic AI geht noch weiter und durchläuft mehrere solcher Denkschleifen, oft mit Tool-Aufrufen und echten Aktionen.
Das Problem: All diese Denkschritte kosten Zeit. Auf herkömmlicher GPU-Hardware bedeutet “genauer” automatisch “langsamer”. Und je komplexer die Aufgabe, desto länger die Wartezeit.
Cerebras hat diesen Zusammenhang als Erster klar formuliert: Schnellere Inferenz ist nicht nur ein UX-Feature, sondern ein Genauigkeitshebel. Wer schneller inferieren kann, kann in derselben Wartezeit mehr Denkschritte ausführen und kommt zu besseren Ergebnissen. Cerebras nennt das die “Cerebras Scaling Law”:
“If you could run inference faster, you could reason more inside the same latency budget — trading surplus speed for higher-accuracy results.” Quelle: Speed and Accuracy (Cerebras)
Das bestätigen auch Produktionsdaten: Laut OpenRouters State-of-AI-Studie 2025 stammt inzwischen mehr als die Hälfte aller verarbeiteten Tokens von Reasoning-Modellen. Die Nachfrage nach Rechenzeit explodiert, und schnellere Hardware wird damit nicht nur zum Komfort-Feature, sondern zur Voraussetzung für genaue Ergebnisse.
Warum KI-Inferenz auf GPUs so langsam ist
Für alle
KI läuft heute auf riesigen Grafikkarten-Clustern. Diese Cluster brauchen enorme Mengen Strom und aufwändige Infrastruktur und kosten hunderte Millionen. Das ist ein Grund, warum KI-Dienste teuer sind und warum Antworten manchmal so lange dauern.
Das Grundproblem: Ein KI-Modell ist viel zu groß, um komplett auf den schnellen Arbeitsspeicher einer Grafikkarte zu passen. Also muss es ständig Daten zwischen langsamem und schnellem Speicher hin- und herschaufeln. Und genau dabei steht die Grafikkarte die meiste Zeit still und wartet.
Für Entwickler:innen
Autoregressive Inferenz besteht aus zwei Phasen: Prefill (parallelisierbar) und Decode. Decode ist der Engpass: Auch mit KV-Caching muss für jedes einzelne Token ein kompletter Forward Pass laufen, sequenziell.
Heutige Modelle sind selbst in den kleinsten Varianten hundertfach größer als der On-Chip-Speicher einer GPU. Deshalb braucht jede GPU ein HBM-Modul (High Bandwidth Memory), angebunden über einen relativ schmalen Memory-Bus mit einstelliger TB/s-Bandbreite. GenAI-Inferenz ist memory-bandwidth-bound: Die Compute-Einheiten warten, bis die Gewichte endlich aus dem HBM bei den Rechenwerken ankommen.
“GPU compute typically sits idle while memory traffic and communication overhead quickly become the bottleneck, especially as models scale and context grows.” Quelle: Speed and Accuracy (Cerebras)
Zwei radikal verschiedene Lösungsansätze
Cerebras: Der größte Chip der Welt
Cerebras geht das Speicherproblem frontal an. Statt einen Wafer in kleine Chips zu zerschneiden und diese dann mit externem Speicher und Interconnects wieder zusammenzustückeln, lässt Cerebras den gesamten Wafer als einen einzigen Prozessor stehen. Der Wafer-Scale Engine 3 ist 5-mal größer als Nvidias B200, mit Compute und SRAM eng verwoben auf einem Die.
Das System besteht aus dem netzwerk-angebundenen Beschleuniger und einem CPU-Cluster, der im Chief/Worker-Modell die Daten mit extremer Geschwindigkeit zum Beschleuniger streamt. Das Ergebnis: massiv höhere On-Chip-Bandbreite, kein Memory-Bottleneck, bis zu 15-mal schnellere Token-Generierung als auf GPUs.
Echte Produktions-Beispiele zeigen, was das bedeutet: AlphaSense verarbeitet auf Cerebras 100-mal mehr Dokumente in der Hälfte der Zeit. Tavus erreicht ~2.000 Tokens/s für Echtzeit-Videogespräche. OpenAIs Codex Spark generiert Code mit über 1.000 Tokens/s.
Taalas: Das Modell wird zum Chip
Taalas geht noch einen Schritt weiter. Statt einen schnelleren Allzweck-Beschleuniger zu bauen, brennen sie jedes einzelne KI-Modell direkt in eigenes Silizium ein. Die Firma bezeichnet ihre Produkte als “Hardcore Models”, Modelle, die buchstäblich zu Hardware geworden sind.
Das beruht auf drei Prinzipien:
- Totale Spezialisierung. Ein Chip, der genau ein Modell ausführt, verschwendet keinen Transistor auf Flexibilität.
- Verschmelzung von Speicher und Compute. Statt Daten zwischen separaten Speicher- und Rechenchips hin- und herzuschieben, vereint Taalas beides auf einem Die mit DRAM-Level-Dichte.
- Radikale Vereinfachung. Kein HBM, kein Advanced Packaging, kein 3D-Stacking, keine High-Speed-I/O.
“The result is a system that does not depend on difficult or exotic technologies, no HBM, advanced packaging, 3D stacking, liquid cooling, high speed IO.” Quelle: The path to ubiquitous AI (Taalas)
Die Analogie, die Taalas selbst zieht, ist treffend: ENIAC war ein raumfüllender Koloss aus Röhren und Kabeln. ENIAC brachte der Menschheit das Wunder des Rechnens, war aber langsam, teuer und nicht skalierbar. Erst der Transistor löste die eigentliche Revolution aus, über Workstations und PCs bis zu Smartphones und allgegenwärtigem Computing. General-Purpose Computing wurde Mainstream, indem es einfach zu bauen, schnell und günstig wurde. KI muss denselben Weg gehen.
Was man wissen sollte, bevor man sich zu früh freut
Beide Entwicklungen sind beeindruckend, aber es gibt wichtige Einschränkungen:
Bei Taalas:
- Das erste Produkt ist ein relativ kleines Modell (Llama 3.1 8B), kein Frontier-Modell.
- Die aggressive Quantisierung (3-Bit und 6-Bit Parameter) führt zu Qualitätseinbußen gegenüber GPU-Benchmarks. Taalas kommuniziert das offen.
- Die zweite Generation (HC2) soll Standard-4-Bit-Formate unterstützen und diese Einschränkungen adressieren.
- Roadmap: Ein mittelgroßes Reasoning-LLM kommt im Frühjahr, ein Frontier-LLM auf HC2 im Winter.
Bei Cerebras:
- Cerebras liefert nachweislich Produktionsleistung bei großen Kunden. Aber der Wafer-Scale-Ansatz hat eigene Herausforderungen bei Yield und Skalierung.
- Die Codex-Spark-Integration ist eine Research Preview für ChatGPT-Pro-Nutzer, noch kein breites Produktionsdeployment.
“15x faster generation, 128k context, now in research preview for ChatGPT Pro users.” Quelle: Introducing GPT-5.3 Codex Spark (OpenAI)
Was sich konkret ändert
Für alle, die KI im Alltag nutzen
-
Weniger Warten bei langen Tasks. Viele Alltags-Prompts sind heute schon schnell genug. Der große Hebel liegt bei komplexen Aufgaben, bei denen man aktuell eher 30-120 Sekunden wartet. Genau dort kann deutlich mehr Durchsatz die Wartezeit auf wenige Sekunden drücken.
-
Genauere Ergebnisse in gleicher Zeit. Wenn die Hardware schneller rechnet, kann die KI mehr nachdenken, bevor sie antwortet und trotzdem schneller fertig sein als vorher. Mehr Geschwindigkeit bedeutet also nicht nur weniger Warten, sondern auch bessere Antworten.
-
Kostenstruktur kann sich verschieben. Wenn Hardware wirklich deutlich günstiger und effizienter wird, verbessert das die Marge pro Anfrage. Ob Anbieter das direkt als niedrigere Preise weitergeben, ist offen — aber der ökonomische Druck in diese Richtung steigt.
-
KI kann an mehr Orte. Wenn ein KI-Chip nicht mehr ein ganzes Rechenzentrum braucht, sondern auf eine einzelne Platine passt, eröffnet das völlig neue Einsatzgebiete. KI direkt im Unternehmen, ohne Cloud, ohne Daten, die das Haus verlassen.
Für Entwickler:innen und Tech-Teams
-
Agentic Workflows werden schneller. Agentische Workflows funktionieren schon heute. Mehr Inferenz-Speed verbessert vor allem die Iterationsgeschwindigkeit und reduziert Leerlauf zwischen Tool-Calls, Reviews und Korrekturen.
-
Geschwindigkeit als Genauigkeitshebel nutzen. Wer auf schnellerer Hardware deployt, kann bei gleichem Latenz-Budget mehr Reasoning-Schritte einbauen. Das eröffnet einen neuen Optimierungsraum: nicht nur schneller antworten, sondern besser antworten, in derselben Zeit.
-
Codex Spark zeigt die Richtung. OpenAIs Entscheidung, ein Modell auf Cerebras statt auf Nvidia laufen zu lassen, ist ein architektonisches Statement. Latency-first Serving wird zur eigenen Infrastruktur-Schicht.
-
Der GPU-Monopol-Gedanke bröckelt. Bisher war die Antwort auf “KI schneller machen” immer: mehr Nvidia-Karten kaufen. Cerebras und Taalas zeigen zwei verschiedene Wege, wie Spezialhardware diesen Ansatz fundamental infrage stellt. Und andere ASIC-Anbieter liefern laut Cerebras nur niedrige einstellige Speedups gegenüber GPUs, weil sie dieselben fundamentalen Beschränkungen kleiner Chips teilen.
Was das für den Mittelstand bedeutet
Diese Entwicklung ist kein reines Silicon-Valley-Thema. Wenn KI schneller und günstiger wird, profitieren gerade kleinere Unternehmen. Die konnten sich die teuren GPU-Cluster nie leisten und waren auf Cloud-Dienste angewiesen, bei denen jede Anfrage Geld kostet.
Spezialisierte, günstige KI-Hardware könnte mittelfristig bedeuten: eigene KI-Systeme im Haus, die schnell, datenschutzkonform und bezahlbar sind. Kein Abo-Modell, keine Abhängigkeit von US-Cloud-Anbietern.
Und es gibt ein konkretes Signal aus der Praxis: Taalas hat sein erstes Produkt mit einem Team von 24 Leuten und Gesamtkosten von 30 Millionen Dollar zur Marktreife gebracht. Das zeigt, dass es nicht hunderte Milliarden braucht, um relevante KI-Hardware zu entwickeln.
Fazit
Wir stehen noch am Anfang. Taalas’ Chips laufen bisher nur mit einem kleineren Modell. Die Cerebras-Integration bei OpenAI ist eine Forschungsvorschau. Aber die Richtung ist klar: Die Ära “wir warten, bis die KI nachgedacht hat” neigt sich dem Ende zu.
Was sich abzeichnet, ist ein Paradigmenwechsel, weg von immer größeren GPU-Farmen, hin zu spezialisierter Hardware, die KI schnell, günstig und überall zugänglich macht. Die ENIAC-Phase der KI geht zu Ende. Was danach kommt, dürfte KI grundlegend verändern.
Quellen
- Taalas: The path to ubiquitous AI
- Taalas Demo: chatjimmy.ai
- OpenAI: Introducing GPT-5.3 Codex Spark
- Cerebras: Speed and Accuracy
- Cerebras: How Cerebras Works
Sie möchten einschätzen, welche KI-Anwendungen in Ihrem Unternehmen heute schon sinnvoll umsetzbar sind und welche Rolle Geschwindigkeit, Datenschutz und Wirtschaftlichkeit dabei künftig spielen? Dann starten Sie mit einer Potenzialanalyse. Gemeinsam prüfen wir, wo in Ihrem Unternehmen echter Nutzen entsteht und welche Entwicklungen für Sie strategisch relevant sind.